A Local Search Engine
April 2021
A tool for searching through every document I've ever read, locally and within seconds.
Reading books and blogs works well enough for gaining knowledge. However both are almost useless as works of reference. Searching through a library of books (physical or digital) is just too slow to be useful. For searching through already read blogposts there seems to be no solution at all. So often I resort to Googling which shows me different, inferior sites instead of returning the things I have already read. This is inefficient and keeps me from drawing new connections between knowledge I've already consumed.
What I now use instead: A local tool that searches through my library of books, saved posts and notes while being as fast as Google. Just like Google, it is maintenance-free and money-free as well. Maintenance free because many self-built tools are a huge timesink, and I want this to save me time. Money free because I intend to keep this tool for many years and don't like continuous payments. All it took was plugging together a handful of well-built tools in a smart way, which I did in a single afternoon.
To get it running I wrote a whole 2 lines of code. The core search as well as the scraping tool work well on Linux, MacOS and Windows. The UI as I have it set up is Linux-only, but there are alternatives.
Step 1: Downloading the content
What is relevant and needs to be searched?
- Every book I've ever read.
- Every good blogpost and website I've read plus all posts on my reading list.
- All Scientific papers I've ever saved.
- Ever note I have written (text, docx, …).
- Lecture slides, presentations and whatever else is relevant.
Archiving books
I like reading books in physical form as it makes taking notes easier. After I've read them I grab an electronic copy from the official online store (=libgen) and save it.
Scraping blogs & websites
Storing snapshots of websites I implemented using Archivebox. Internally this uses a headless Chromium to access the site and downloads it as a singlepage HTML file using SingleFile. I used to have ArchiveBox configured to save screenshots as well, but the singlepage HTML turned out to be more faithful in almost every case. In my experience the singlepage HTML displays exactly like the original page without relying on any external content.
Everyone whose ever done any scraping knows that websites are a cesspool of complicated edgecases, kept alive by gracious rendering engines.
ArchiveBox has so far handled all of them well.
Storage volume is roughly 1MB per scraped site.
ArchiveBox can be run within docker-compose without any installation or dependency headaches and is simple to update via docker-compose update.
To figure out which websites I care about I run a search tool (ripgrep) through my local notes and match a Regex. Other interesting approaches that are similarly hands-off: using browser bookmarks, extracting complete browsing history, … On Linux this whole scraping process is a short cron-script: ArchiveBox can download Youtube videos as well, but they aren't very useful and take up too much space.
# Search org-roam notes for simple link regex
# Pipe all result (except youtube links) into a tmpfile
rg '\b(?:https?://)(?:(?i:[a-z]+\.)+)[^\s,\]]+\b' \
--only-matching --no-filename --no-line-number --no-heading \
--ignore-file /home/simon/Dropbox/org-roam/.gitignore \
/home/simon/Dropbox/org-roam \
| grep -v -E '(https?://www.youtube.com/|https?://youtu.be)' \
> /tmp/org-roam-url-dump.txt
# add all links from tmpfile to archivebox
/home/simon/.local/bin/docker-compose -f \
/home/simon/archivebox/docker-compose.yml \
run archivebox add < /tmp/org-roam-url-dump.txt
Step 2: Search
For the search part I use Recoll, which is excellent and easy to use. It builds an index by going through all directories and files you tell it about, extracting any text found within and saving it in a compressed index. This might take a few minutes on the first run, but subsequent index updates are fast and can run in the background.
I configured it to update the index every day, and to index my whole home folder while excluding irrelevant datatypes (like code or images).
User Interface
I access the search through zzzfoo, a small script that pops up rofi and then runs the given query in Recoll. The results are displayed in another rofi buffer. When I select a result the file is opened with whatever program is configured as standard for this filetype. zzzfoo doesn't open PDFs at the page where the search term was found, but at the beginning of the document. Changing this was easy but contains some very ugly hacks which I'm ashamed of, so I haven't uploaded it anywhere yet. You can email me to get the rough version.
Rofi only works on Linux. On MacOS or Windows I'd just open Recoll directly, which might not look as nice but works just as well.
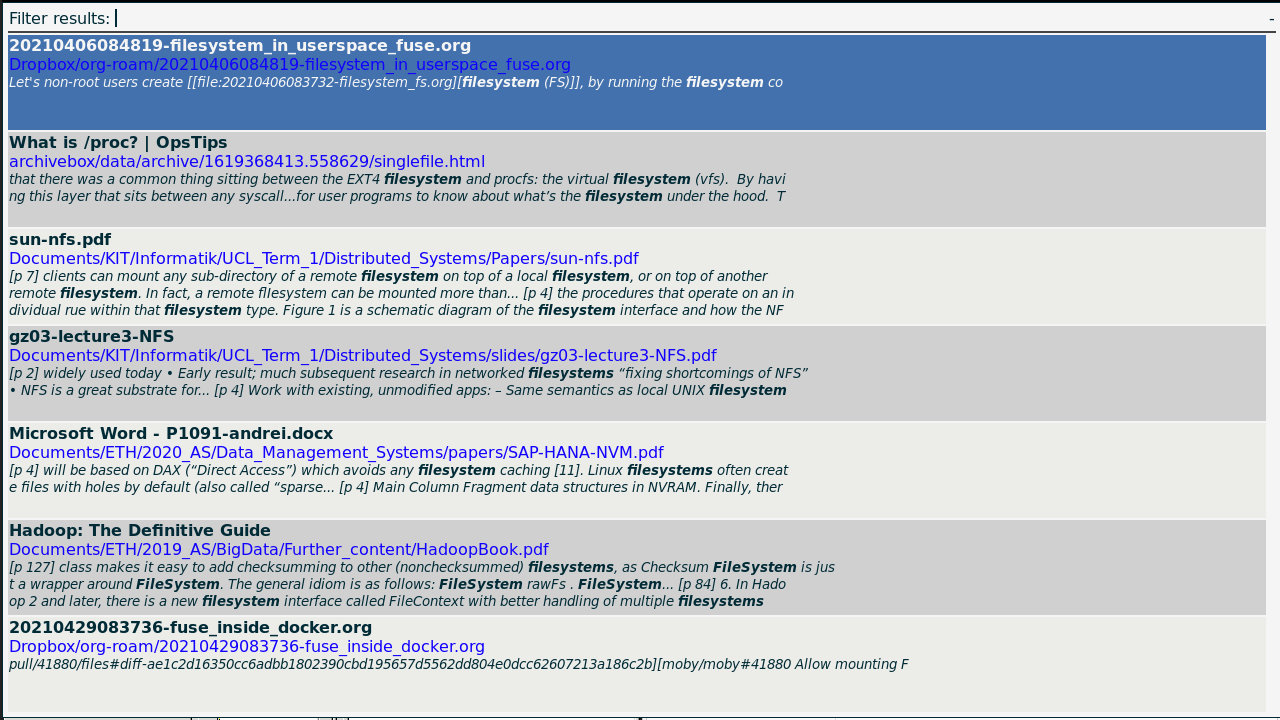
Figure 1: The search results for "Filesystems", showing the various filetypes and some generated abstracts.
Conclusion
This tool saves me time, enables new workflows and doesn't require any maintenance. I've had it running for a few weeks now and use it multiple times every day to do reference lookups or read-up on terms from old blogposts. Frequently the tool returns me papers and posts which I had completely forgotten about.
Building your own is fairly simply: First download ArchiveBox and configure it. Then install Recoll and setup its index to track all documents you care about. Last use whatever scripting language you're most comfortable with to extract all URLs from your notes and pipe them to ArchiveBox.
Next: Code Search
I want to build something similar but for code, which I hope would speed up many mundane tasks in programming. It would allow my to copy-past my own code, and save me from having to look up documentation. I haven't yet figured out a way to build a code-search as easily as the text-search described here. If you have a good idea, email me at [firstname]@siboehm.com!